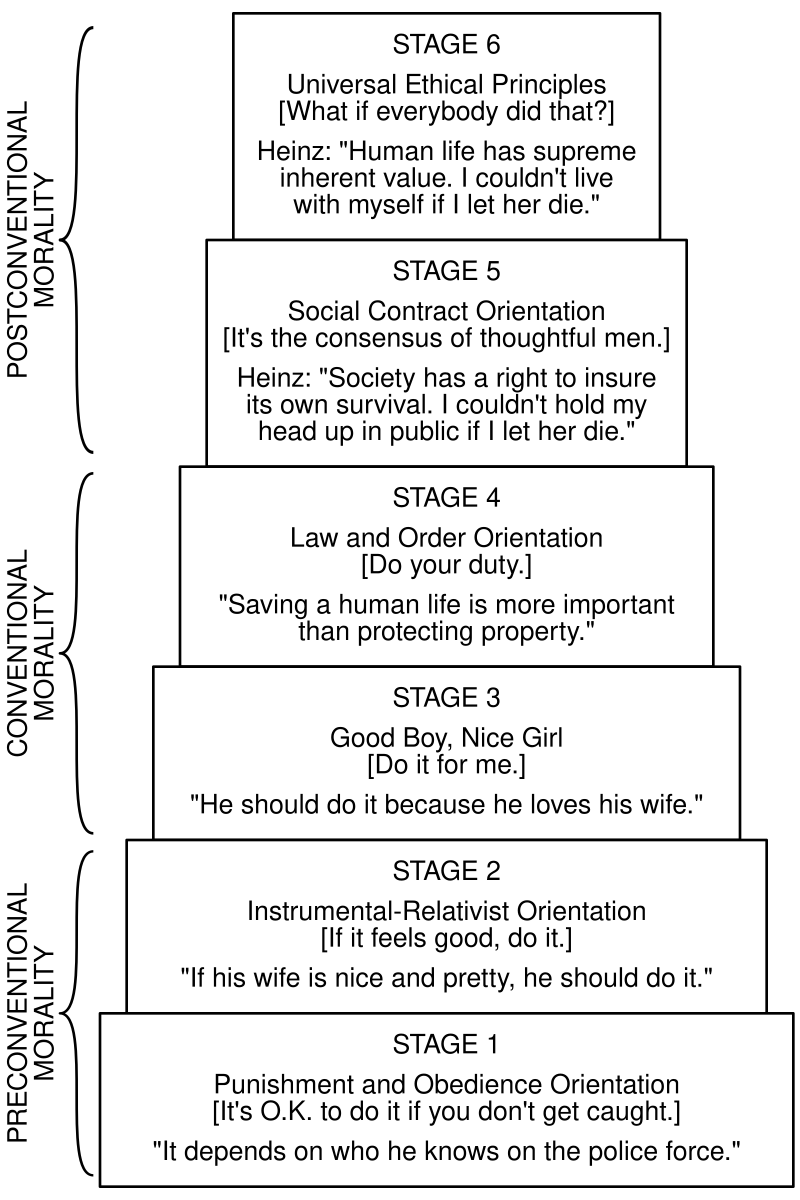
話先說在前頭,Kohlberg 在 1958 年所提出的道德發展階段,後續受到很多的挑戰,也不是當前學術界的主流觀點。但相較於新近的道德心理學研究,Kohlberg 的理論有其時代特色:結構主義。簡單的說,就是他的理論提供了一個明確的形式與方向:人的道德觀區分成若干階段,從個人到社會,從幼小到成年;言下之意就是:從劣到優。
時至今日,我們自然不必完全服膺他的理論,但 Koberg 提出的架構依然有其參考價值。他的理論把人的道德發展分為六個階段:
- 服從與懲罰定向(避罰服從:「我會不會挨罰?」)
- 利己主義定向(相對功利:「對我有何益處?」)
- 人際和諧與一致(尋求認可:「會不會丟臉?」)
- 維護權威與社會秩序定向(社會法制、法律與秩序:「是否合法?」)
- 社會契約定向(「法律/規則是否公平?」)
- 普遍倫理原則(原則與良心定向)
前三個階段的劃分,受到的批評比較少,因為這段發展基本上反映了人類從生物本能走向社會化的歷程。
而後面的階段就飽受攻擊,有人說他只強調正義,忽視其他的價值,沒有充分顧及到其他道德層面。也有人批評他的理論單純基於白人男性觀點(他的實驗初期只有男性受試者),Gilligan 以女性的觀點提出了「關懷倫理學」,來修正 Koberg 的理論。Gilligan 將 Koberg 的「三期六階段」簡化:
- 前成規期:個人生存
- 成規期:自我犧牲為善
- 後成規期:非暴力原則(不得傷害他人或自己)
相較於 Koberg 試圖指出「正確的發展方向」,Gilligan 的論述更像是畫出「道德的底線」,的確是相當不同的觀點。
Koberg 的道德發展階段後續發展出一些相關的心理測驗(Defining Issues Test, DiT),而關懷倫理學後續也有更多細緻的論述。但新近的道德心理學研究,則較聚焦在神經科學的發現,探討個人的道德敢試怎麼來的。有興趣的讀者,可以參考最近謝伯讓老師在廣播節目裡的介紹。
之所以想到要寫這個題目,主要是深深的感受到整個世界氛圍的分化與對立。
每個人都是自身經驗的囚徒,所以每個人都會有獨有的價值觀,每個人心目中也有各自以為的正義。而很可悲的,我們每個人也都覺得「我的正義比你的正義更正義」,「我的價值觀比你的更高尚」。這是人性。
社群媒體連結了大家,但同時也強化了對立:當我可以很容易的找到跟我觀點像似的人(同溫層),我就更容易強化自己的信念,更勇於表達自己不同的想法,同時,很不幸的,也更不願意聽見不同的聲音。
那麼,接下來就是行為的選擇了。如果我的正義比你的正義更正義,如果我的價值觀比你的價值觀更高尚,我是不是就可以鄙視你、侮辱你,甚至傷害你?
行為的底線在哪裡,大抵上決定了文明發展的程度:沒有底線,那麼我們就跟生物界的弱肉強食無異;能夠做到不互相殺害,那麼物種就有了繁衍成長的機會;彼此傷害的程度降低、協作複雜度提高,基本上是我們從茹毛飲血到今日繁華所依循的路線。
我不知道這個路線是不是就是最高尚的,但我只能說,我期待大家至少能守住「非暴力原則」這條線,不然我們的文明發展恐怕很快就要到盡頭了。



")









")



